DIT STAAT EVENTUEEL OOK BIJ SHORT FORMS PAGINA
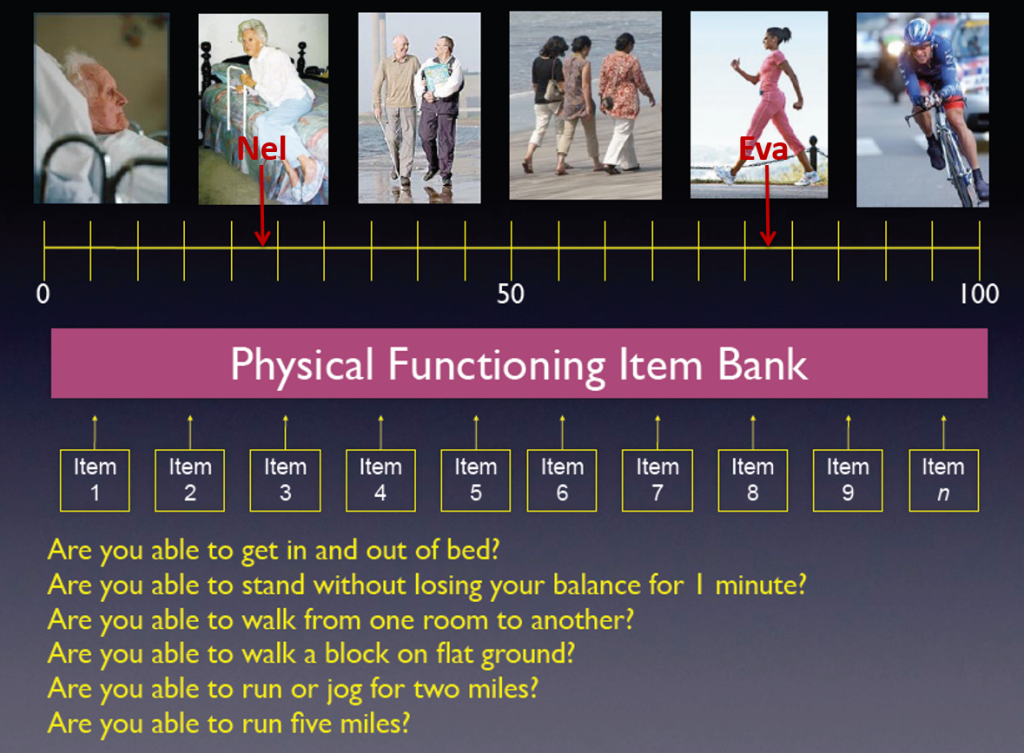
Uit een item bank kunnen short forms worden gemaakt, door een selectie van items te kiezen uit de item bank. Bij het kiezen van de items wordt gebruik gemaakt van kennis over de locaties van de items op de meetschaal. Er kan een selectie van items worden gekozen die de hele range van de schaal dekt, of juist een specifiek deel. Bijvoorbeeld, bij het maken van een short form voor het meten van lichamelijk functioneren voor een oudere populatie zullen vooral ‘makkelijke’ items worden gekozen, terwijl voor een populatie van atleten vooral ‘ moeilijke’ items worden gekozen. Daarnaast wordt rekening gehouden met het discriminerend vermogen van elk item, dat ook met het IRT model wordt berekend. Ook kan rekening worden gehouden met de relevantie van de items voor een specifieke doelgroep.
Bij elke short form die uit een item bank is gemaakt, krijgen personen een score op dezelfde meetschaal als de item bank. Scores van verschillende short forms kunnen dus direct met elkaar vergeleken worden.
PROMIS heeft voor elke item bank één of meerdere short forms gemaakt die de hele range van de schaal dekken. Dit worden ‘standard short forms’ genoemd. Voorbeelden zijn de 4a, 6a en 8a short forms.
#Hoe werkt een CAT?
Als de vragen in een itembank met behulp van een IRT model op volgorde zijn gezet, kan de itembank worden afgenomen middels computer adaptief testen (CAT). Bij een CAT wordt meestal eerst een vraag uit het midden van de meetschaal gesteld. Afhankelijk van het antwoord kiest de computer een makkelijkere of een moeilijkere vraag. Na elke gestelde vraag wordt de positie van de persoon op de meetschaal geschat met een bijbehorende meetfout (standaard error). De meetfout wordt steeds kleiner naarmate er meer vragen zijn beantwoord omdat we steeds beter weten waar de persoon zich precies op de meetschaal bevindt. Als de meetfout een vooraf bepaalde grenswaarde heeft bereikt of als een vooraf bepaald maximaal aantal vragen is gesteld, stopt de CAT.
Het voordeel van een CAT is dat personen relevantere vragen krijgen (als je weet dat iemand veel moeite heeft met het maken van een wandeling van 15 minuten, hoe je niet meer te vragen of iemand 8 km kan hardlopen). Ook krijgen personen veel minder vragen omdat je door deze slimme manier van vragen sneller een nauwkeurige schatting kunt krijgen van waar iemand zich op de meetschaal bevindt. Gemiddeld heeft een CAT 3 tot 7 vragen nodig om een betrouwbare score te leveren waar je met een gewone vragenlijst 20 vragen voor nodig zou hebben.
Het gebruik van CAT wordt aangeraden voor situaties waar nauwkeurige metingen gewenst zijn, bijvoorbeeld in wetenschappelijke studies waar PROMIS instrumenten als primaire uitkomstmaat gebruikt worden en bij het monitoren van de gezondheidstoestand van individuele patiënten in de zorg.
Bij het gebruik van CAT kunnen verschillende personen verschillende vragen krijgen. Toch krijgt elke persoon een score op dezelfde meetschaal en daarom zijn scores met andere personen te vergelijken, ook als deze niet dezelfde vragen hebben beantwoord.
PROMIS heeft voor elke item bank een CAT ontwikkeld.
#Interpretatie van de IRT meetschaal
Elke vragenlijst of item bank die met IRT wordt ontwikkeld, krijgt zijn eigen meetschaal, die bepaald wordt door het IRT model. De standaard IRT meetschaal (theta genoemd) heeft een gemiddelde van 0 met een SD van 1 in de populatie waarin het IRT model wordt geschat (het calibration sample).
Bij PROMIS is ervoor gekozen om de meetschaal om te rekenen naar een T-score, door er 50 bij op te tellen (0 wordt 50) en te vermenigvuldigen met 10 (SD wordt 10). Daarnaast is er voor gekozen om de meetschaal zodanig weer te geven dat een score van 50 gelijk staat aan het gemiddelde van een relevante referentie populatie (centering sample). In de meeste gevallen is dat een algemene populatie.
Kijk hier voor meer informatie over de calibration samples en referentie populaties van PROMIS: Reference Populations (healthmeasures.net)